The Cimetrix Connectivity Group of PDF Solutions is happy to announce that Cimetrix CIMControlFrameworkTM (CCF) version 6.0 is now available for download.
CCF is a software development kit (SDK) that enables users to design and implement a high-quality equipment control solution using provided components for supervisory control, material handling, operator interface, platform and process control, and automation requirements. CCF is built on the reliable Cimetrix connectivity products which provide GEM/GEM300/EDA interface functionality.
We have previously done a series of blog posts on the functionality of CCF. The same great functionality users have come to expect with CCF is still available, but in a cleaner, slicker, easier to use package.
Reorganized directory structure
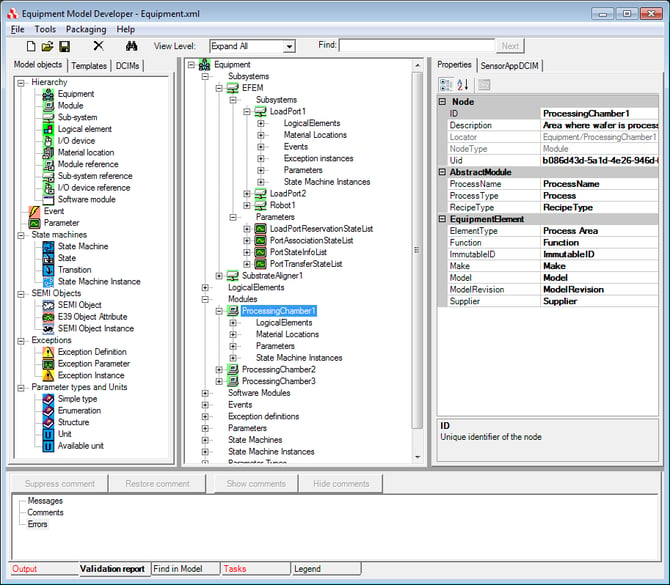
In versions before CCF 6.0, core CCF packages (packages provided by CCF) were contained in the same directory as sample code and runtime files. This made it more difficult for CCF users to understand what code was required to be customized and what code was basic to CCF. (Note: you can still customize the basic CCF functionality, but it is not required.) In this release, we modified the directory structure to identify more clearly what is core CCF and what is sample or custom code. This is closer to the structure followed by CCF applications. The following diagram shows the new structure:
 In addition to clarifying CCF components, the new structure allows us to easily develop samples for additional equipment types. New samples will be added in future versions of CCF.
In addition to clarifying CCF components, the new structure allows us to easily develop samples for additional equipment types. New samples will be added in future versions of CCF.
New WPF framework
Since CCF started providing a Windows Presentation Foundation (WPF) framework, we have received feedback on WPF features user would like added to the framework. Also, our engineers have continued to improve their WPF expertise, which has led to other improvements. CCF 6.0 includes the requested changes and best practice improvements in the new WPF framework. Some of these changes include:
- Simplified hierarchy which makes it easier to understand which objects to inherit from.
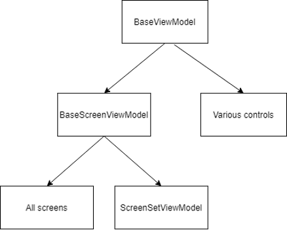
- Centralized style elements to allow users to change the look and feel (skin) of the operator interface to meet their needs.
- Enhanced controls library that provides common controls for use in creating equipment control.
- Increased E95 compliance, available with a configurable control panel.
- Accelerated screen creation is possible with the change in hierarchy organization and the enhanced control library.
- Richer set of native WPF screens. In earlier versions, CCF had several native WPF screens, but also had many screens created with WinForms and hosted in WPF. CCF 6.0 has all native WPF screens in the WPF sample operator interface. These screens can be reused, customized, or replaced. (Note: WinForms screens are also still available in CCF 6.0.)
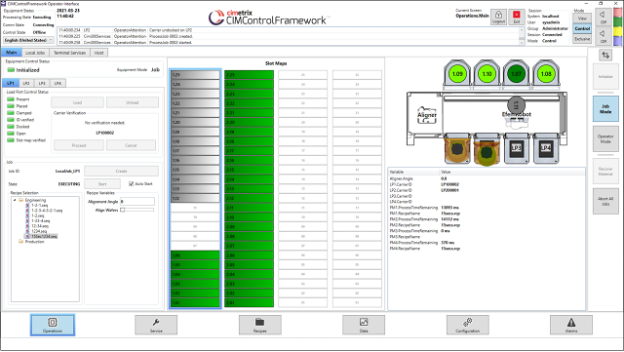
The following image shows the main screen of the WPF operator interface for the CCF atmospheric equipment sample application. Most of the controls on the screen are available for use and customization by CCF developers.
 Updated samples
Updated samples
CCF has contained fully functional atmospheric and vacuum sample applications for many years. Over the years, we have improved the functionality for scheduling, simulation, and device interface interaction. However, the samples had always remained the same. With CCF 6.0, the atmospheric and vacuum sample applications were updated to take advantage of the other changes that have been made in CCF. These changes to the samples make them more useful in illustrating the proper use of CCF and providing a better starting point for creating custom applications.
Spring cleaning
CCF was originally released the summer of 2011 making it 10 years-old. Over the years, CCF has had several methods, objects and devices become obsolete. They were not removed from the product for backward compatibility reasons, but they were marked as obsolete. Because CCF 6.0 is a major release, we took the opportunity to do some spring cleaning and remove the obsolete items. CCF is now cleaner and tighter, and using it is much clearer.
Training material and upgrade guide
All the PowerPoint slides, lab documents, and corresponding solutions used for training developers on CCF have been updated for CCF 6.0. We have already successfully used the new training materials with a few customers to help them get started with their equipment control application development.
As part of CCF 6.0, we provide a CCF 5.10 to CCF 6.0 Upgrade Guide that contains detailed instructions on how to migrate applications created using previous versions of CCF to CCF 6.0.
Conclusion
We have been looking forward to the CCF 6.0 release for a long time and are excited for developers to get started using it. We are confident existing users will like the changes and that new users will have a good springboard in getting started with their equipment control application needs. We look forward to working with you and hearing from you.
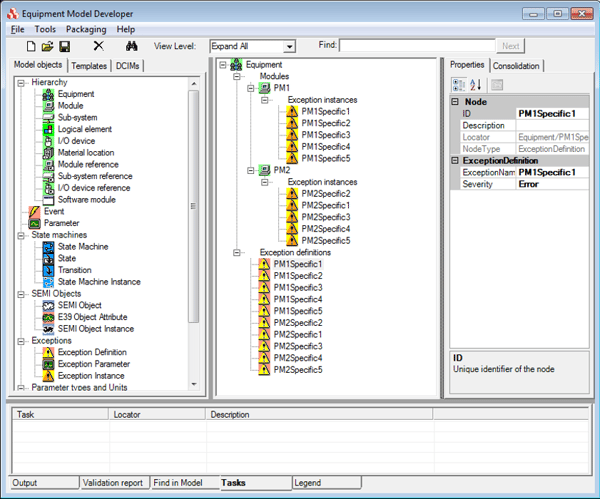 However, with this approach, if each module has 5000 exceptions, 200 modules would result in 1 million exception instances with a corresponding 1 million exception definitions. The system resources required to deploy and maintain this model are very large.
However, with this approach, if each module has 5000 exceptions, 200 modules would result in 1 million exception instances with a corresponding 1 million exception definitions. The system resources required to deploy and maintain this model are very large.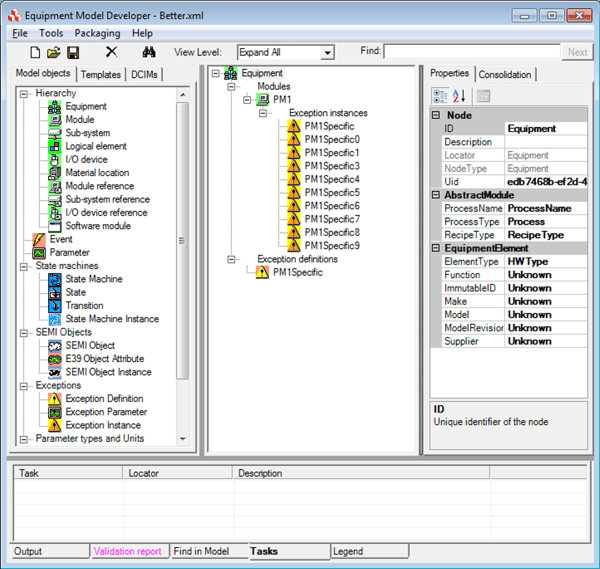 In this example, we can see that the process module has ten exception instances, but now there is only one set exception definition. Using this approach, if each module has 5000 exception instances, 200 modules would still result in 1 million exception instances, but we would now only have 200 exception definitions (one for each module). This is a significant reduction, but still quite large.
In this example, we can see that the process module has ten exception instances, but now there is only one set exception definition. Using this approach, if each module has 5000 exception instances, 200 modules would still result in 1 million exception instances, but we would now only have 200 exception definitions (one for each module). This is a significant reduction, but still quite large.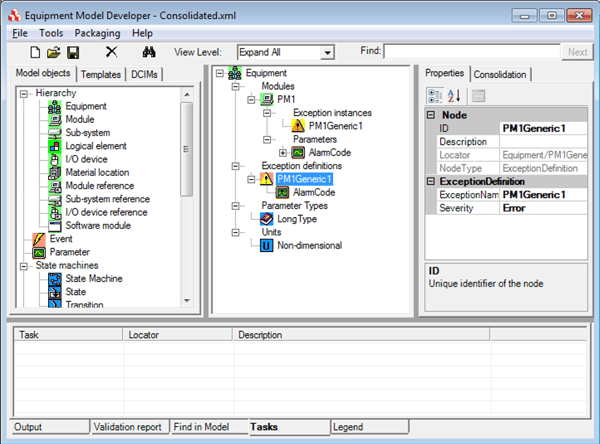 The process module in the model above only has one exception. The transient parameter AlarmCode would contain the information about what caused the exception to be triggered. It is possible to have multiple exception parameters if additional information is necessary (sub error code, description, etc.)
The process module in the model above only has one exception. The transient parameter AlarmCode would contain the information about what caused the exception to be triggered. It is possible to have multiple exception parameters if additional information is necessary (sub error code, description, etc.)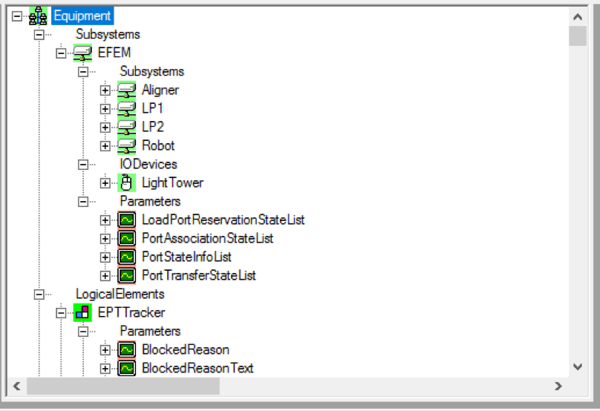





 Buffering
Buffering